Multimodal Adversarial Defense for Vision-Language Models by Leveraging One-To-Many Relationships
Abstract
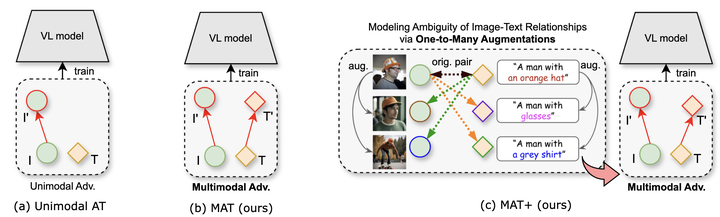
Vision-Language Models (VLMs) are increasingly adopted in practical applications, but remain vulnerable to adversarial perturbations. Existing adversarial fine-tuning methods often rely on one-to-one image-text supervision and may overfit to narrow language cues. This work studies multimodal defense with one-to-many relationships between images and textual descriptions, improving robustness under stronger attack settings while retaining clean performance.
Type
Publication
WACV 2026