Closer Look at the Transferability of Adversarial Examples: How They Fool Different Models Differently
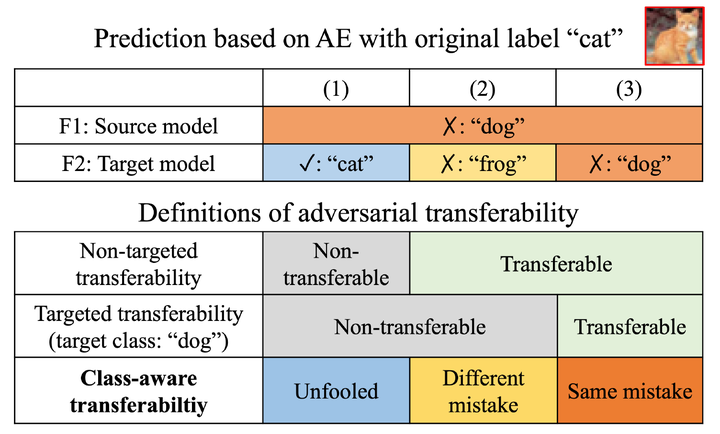 Image credit: Unsplash
Image credit: UnsplashAbstract
Deep neural networks are vulnerable to adversarial examples (AEs), which have adversarial transferability: AEs generated for the source model can mislead another (target) model’s predictions. However, the transferability has not been understood in terms of to which class target model’s predictions were misled (i.e., class-aware transferability). In this paper, we differentiate the cases in which a target model predicts the same wrong class as the source model (“same mistake”) or a different wrong class (“different mistake”) to analyze and provide an explanation of the mechanism. We find that (1) AEs tend to cause same mistakes, which correlates with “non-targeted transferability”; however, (2) different mistakes occur even between similar models, regardless of the perturbation size. Furthermore, we present evidence that the difference between same mistakes and different mistakes can be explained by non-robust features, predictive but human-uninterpretable patterns: different mistakes occur when non-robust features in AEs are used differently by models. Non-robust features can thus provide consistent explanations for the class-aware transferability of AEs.